I recently competed in Google DeepMind’s Measuring Progress Toward AGI hackathon on Kaggle. The competition splits intelligence into cognitive pathways and asks you to build a benchmark for one of them—I picked attention: can a model focus on what matters and ignore what doesn’t?
It sounds like the most measurable thing in the world. It isn’t.
Why attention is hard to measure#
The problem is that in natural language, “what matters” is negotiable. Is that clause a distractor or critical context? Should the rule stated mid-passage override the pattern from training? These judgements bleed into interpretation and memorised priors, which makes attention nearly impossible to isolate: a model that looks distracted may simply disagree about what’s important, and a model that looks focused may just be pattern-matching phrasings it has seen before.
My favourite example is the classic shifting-attention probe: “from now on, call Alice ‘Bob’.” When a model fails that, did its attention fail—or does it just have a stronger prior on Alice than the local instruction can overwrite? You can’t tell. The measurement is contaminated by vocabulary frequency and training distribution before it begins.
So I made relevance deterministic#
My approach was to take the judgement call out entirely. In a 3D coordinate space, whether a point’s definition matters to a query is not an opinion—it’s a mathematical fact you can verify algorithmically. Spatial reasoning has been used to test LLMs before; the idea in ZelusBench is to aim it at attention specifically, because geometry buys you exactly the properties an attention benchmark needs:
- Relevance is a fact. A noise point either feeds into the query’s dependency chain or it doesn’t—no debating its “distractor-ness”.
- A pure mental-set shift exists. Reflecting the space over the y-axis invalidates the model’s coordinate map without making any token more or less familiar. It’s the Alice/Bob test with the vocabulary bias surgically removed.
- Contamination is impossible. Every scenario is synthetically generated from a seed at evaluation time. You’re measuring attention, not recall.
- No LLM judge. Each scenario carries a dependency graph that resolves to closed-form ground truth, so scoring is exact and free.
Scenarios introduce points through chains of relative statements—“G is 2.8 units from F in the direction (0.6, 0.4, 0.8)"—so the model must build its representation incrementally, then answer a question with exactly one right answer. From there, one generation knob per task isolates each of the three canonical attention faculties from cognitive science: selective (inject irrelevant chains, scale the noise), sustained (deepen the chains, test maintenance without drift), and shifting (apply a mid-scenario transformation that forces the model to discard its map and rebuild).
What the models revealed#
I evaluated a spread of frontier models, and the headline is that they are very different—overall scores ranged from ~0.79 (Gemma 4 31B) down to ~0.30 (GPT-5.4 mini). But the interesting part is the sub-task breakdown, which reads like a cognitive profile of each model:
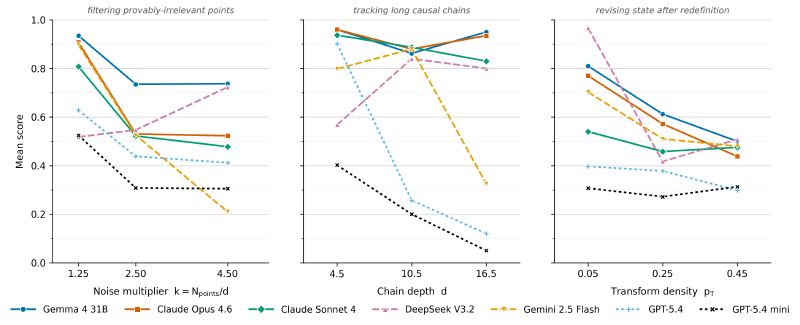
A few things jumped out:
- Noise genuinely distracts models. Claude Opus fell from 0.91 to 0.53 as the noise ratio increased—quantified distractibility, exactly the failure mode attention theory predicts.
- Long chains expose context limits. Claude Sonnet and Opus held ~0.83–0.94 on the longest chains while Gemini 2.5 Flash collapsed to 0.33 and GPT-5.4 slid from 0.90 to 0.12—early relations simply get forgotten.
- Nobody can shift. High-complexity transformations beat every model; the best score was 0.5. Abandoning a built-up mental map turns out to be a universal weakness that static Q&A never exposes.
- Profiles diverge in odd ways. DeepSeek V3.2 tracks changes brilliantly (0.97 shifting_low) but filters noise poorly (0.52 selective_low); Gemini 2.5 Flash filters well right up until it catastrophically doesn’t (0.90 → 0.21).
That last point is really the thesis: two models with similar overall scores can have completely different profiles. The useful question stops being “which model is better?” and becomes “which model is better for what kind of thinking?”
See it in action#
I put together a short video walkthrough of the benchmark and results:
To learn more—the full task construction, scoring tiers, dataset design, and the complete results—head to my full writeup on Kaggle.